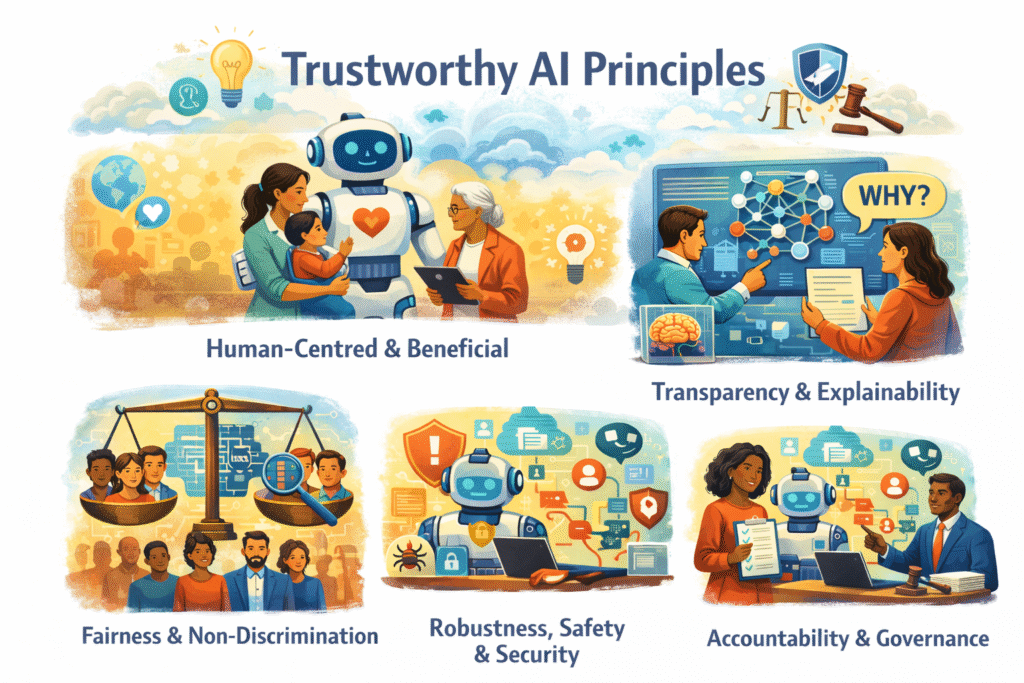
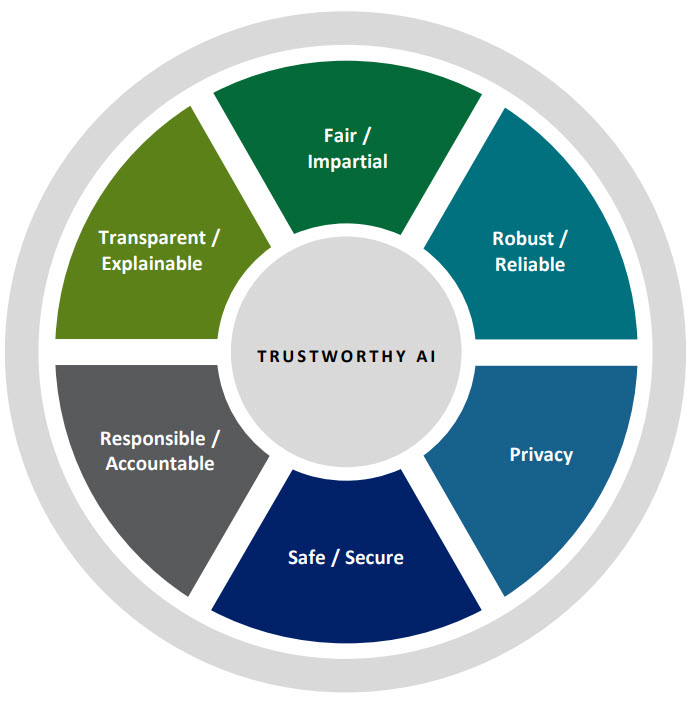
Trustworthy AI means designing, developing, deploying, and using AI systems in ways that are human-centred, fair, transparent, safe, secure, and accountable. These principles reflect international consensus, including the OECD AI Principles, and are widely aligned with UK and EU regulatory approaches.
AI should enhance human wellbeing and dignity, supporting people rather than replacing meaningful human judgement.
Key points
Respect human rights and democratic values
Maintain meaningful human oversight
Focus on clear social benefit
AI systems should avoid unjustified bias and discrimination, both in design and real-world impact.
Key points:
Identify and mitigate bias in data and models
Test impacts across diverse groups
Design for inclusion and accessibility
People should understand when AI is used and have appropriate insight into how decisions or outputs are produced.
Key points
Clearly signal AI use
Provide explanations proportionate to risk
Document purpose, limits, and assumptions
AI should perform reliably under normal and adverse conditions and be resilient to misuse or attack.
Key points
Rigorous testing before and after deployment
Ongoing monitoring for drift and failure
Strong security and misuse protections
Responsibility for AI outcomes rests with organisations and people, not with the technology itself.
Key points
Clear ownership and decision accountability
Audit trails and documentation
Mechanisms for challenge, oversight, and redress
Trustworthiness Checklist
□ Is the AI’s purpose clearly beneficial and justified?
□ Are fairness and bias risks identified and mitigated?
□ Can affected people understand and challenge outcomes?
□ Is the system robust, safe, and secure over time?
□ Are accountability and governance clearly assigned?
Risks and Mitigations
Over-reliance on automation → Human-in-the-loop controls
Hidden bias or exclusion → Impact assessments and diverse data
Loss of trust due to opacity → Clear communication and explainability
Governance Takeaway
Trustworthy AI is not a one-off technical task. It requires continuous organisational commitment, leadership accountability, embedded risk management, and regular review across the AI lifecycle.
In discussions about trustworthy and responsible AI, data governance is now widely recognised as foundational. Yet many organisations still struggle with a practical question:
How do we actually control data exposure inside AI systems without breaking usability, productivity, or workflows?
For internal corporate AI use cases such as training, retrieval-augmented generation, analytics, and AI agents, traditional controls are proving insufficient. Perimeter security, application-level permissions, and even model-centric safeguards all fail at the same point. Once data is accessed, it is effectively exposed.
A more effective approach is emerging. One that brings Zero Trust principles directly to the data layer itself.
The limits of traditional data protection for AI
Most enterprise data protection strategies assume one of two models.
First, perimeter trust. If a user or system is inside the network or application boundary, data is assumed to be safe.
Second, application trust. Access control is enforced by the application, database, or AI
service consuming the data.
Both models break down in AI environments.
AI systems:
Aggregate data from multiple sources
Repurpose data beyond its original context
Retain statistical representations of sensitive information
Operate across tools, models, and agents
Expose data indirectly through outputs, logs, and inference behaviour
Once data enters an AI pipeline, traditional access control loses precision. Entire documents are shared when only a few fields are required. Sensitive data is copied into prompts, embeddings, or logs. Controls are applied too late, too broadly, or not at all.
This is a data governance failure, not a model failure.
A data-centric shift: protecting the datum, not the document
A more resilient approach is context-preserving selective encryption.
Instead of encrypting whole files or databases, this approach allows encryption down to a single datum. A field, value, paragraph, or attribute can be protected while the rest of the document remains intact and readable.
The defining characteristics matter.
Selective encryption at field level Only sensitive elements are encrypted. Non-sensitive context remains visible.
Context preserved The document remains usable in its native application such as Word, PDF, spreadsheets, or internal systems. Workflows are not broken.
Cryptographic enforcement Access is enforced by cryptography rather than application logic or implicit trust.
This represents a fundamental shift. The protection travels with the data wherever it goes.
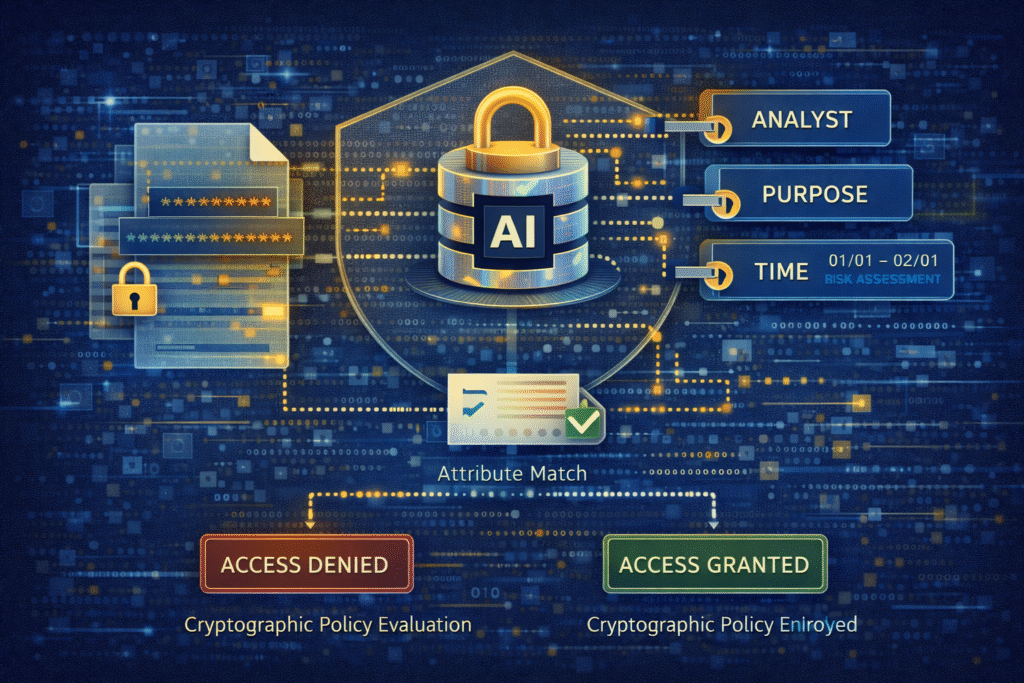
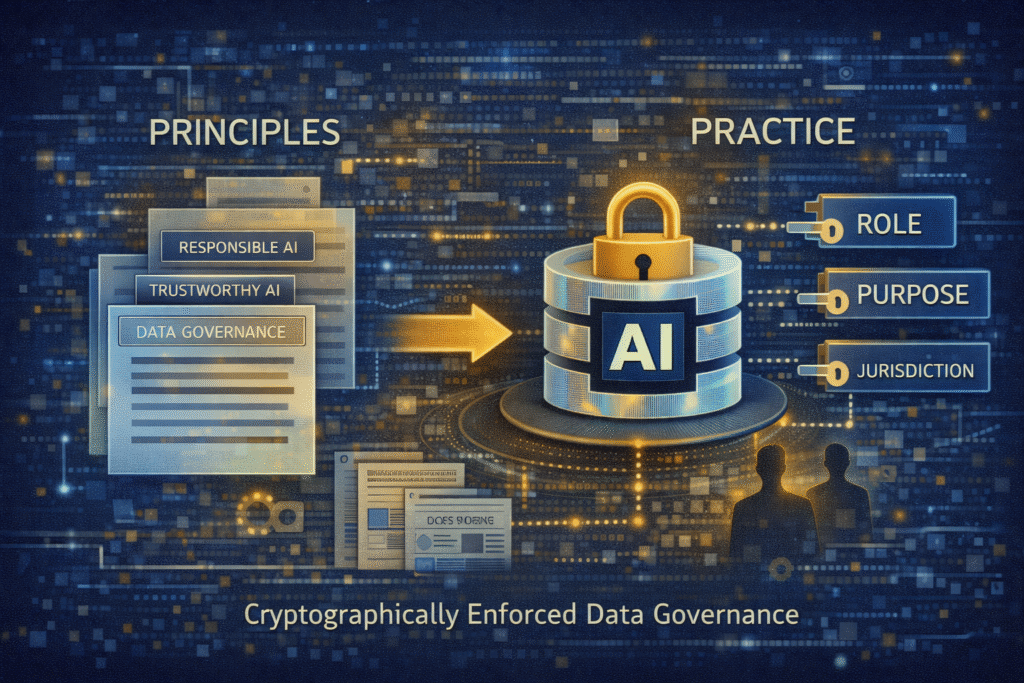
Attribute-based access control enforced cryptographically
Selective encryption becomes far more powerful when combined with cryptographic Attribute-Based Access Control (ABAC).
In this model:
Access decisions are based on attributes such as role, clearance, jurisdiction, purpose, time, or project
Policies are enforced cryptographically, not just administratively
Decryption occurs only when attributes and policy conditions are satisfied
This matters enormously for AI.
AI systems, agents, and users no longer receive all-or-nothing access. They receive only the data they are explicitly authorised to see, even when working on the same document or dataset.
This aligns directly with:
Least-privilege principles
Purpose limitation under GDPR
Internal data segregation requirements
AI risk containment strategies
Full auditability: governance you can evidence
Trustworthy AI requires more than prevention. It requires accountability.
A strong data-layer approach includes complete and immutable audit trails that capture:
Who accessed which data
When access occurred
Under which attributes and policies
For what declared purpose
This transforms data governance from policy statements into evidence-backed control.
For AI governance, this is invaluable:
Incident investigations become tractable
Regulatory questions can be answered precisely
Internal misuse can be detected and addressed
AI system behaviour can be contextualised and explained
Governance becomes auditable by design.
Zero Trust applied where it matters most
Zero Trust is often discussed in terms of networks, identities, or endpoints. But AI exposes the limitation of that thinking.
AI does not respect perimeters. It consumes data wherever it is allowed to flow.
By applying Zero Trust directly to the data layer, organisations:
Remove implicit trust in applications and systems
Reduce blast radius when AI systems misbehave
Prevent over-exposure of sensitive information
Maintain usability without sacrificing control
This is Zero Trust in its most literal form:
never trust access to data unless cryptographically proven and policy-justified.
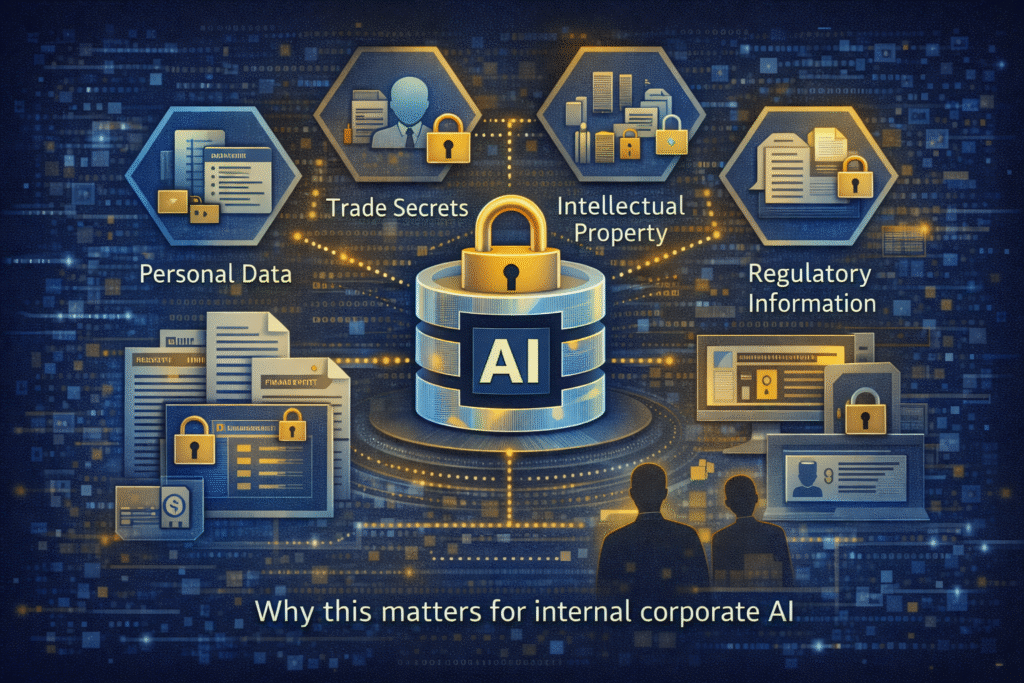
Why this matters for internal corporate AI
Internal AI use cases are often assumed to be lower risk. In reality, they frequently involve the most sensitive data an organisation holds. This includes:
Personal data
Commercially sensitive information
Intellectual property
Strategic plans
Regulatory material
Selective encryption combined with cryptographic ABAC allows organisations to:
Use internal data for AI safely
Enable RAG and analytics without wholesale exposure
Support AI agents without granting excessive access
Preserve privacy while maintaining productivity
It is one of the strongest privacy-preserving patterns currently available for enterprise AI.
From principles to practice
Responsible and trustworthy AI is often discussed in abstract terms. Trust, however, is not created by intent. It is created by design choices.
Moving from model-centric controls to data-centric, cryptographically enforced governance is one of the most important steps organisations can take today.
Because in AI, the most reliable way to control outcomes remains simple.
Control the data.
Final thought
If data governance is the foundation of trustworthy AI, then it follows that Zero Trust must ultimately live at the data layer.
Not at the perimeter. Not only in applications. But inside the data itself.
As organisations race to adopt generative AI, agents, and data-driven automation, conversations about trustworthy and responsible AI often focus on ethics statements, model transparency, or regulatory compliance.
These are important. But they are not where trust begins.
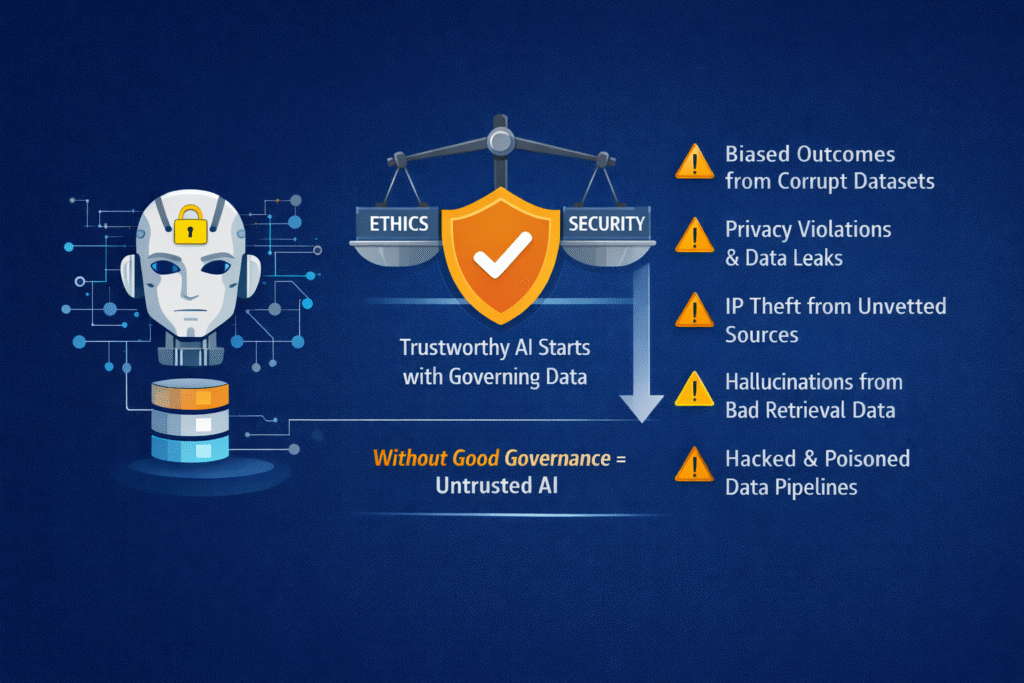
Trustworthy AI begins with data governance.
Before models are trained, before prompts are written, and before outputs are evaluated, AI systems inherit their behaviour, risks, and limitations from the data they consume. If data is poorly governed, no amount of downstream controls can fully restore trust.
Why data governance is the foundation of AI trust
AI systems do not reason in the human sense. They learn statistical patterns from data and apply those patterns at scale. This means that data choices are governance choices.
Every decision about:
what data is collected,
where it comes from,
how it is processed,
who can access it,
how long it is retained, and
how it is reused
directly shapes whether an AI system is lawful, safe, fair, secure, and accountable.
In practice, most AI failures attributed to “model risk” are actually data governance failures:
Biased outcomes rooted in unrepresentative datasets
Privacy violations caused by uncontrolled training data
Intellectual property exposure from scraped or licensed-unclear sources
Hallucinations amplified by poorly governed retrieval data
Security incidents driven by data leakage or poisoning
Trustworthy AI does not emerge at inference time. It is established much earlier, through disciplined data governance across the AI lifecycle.
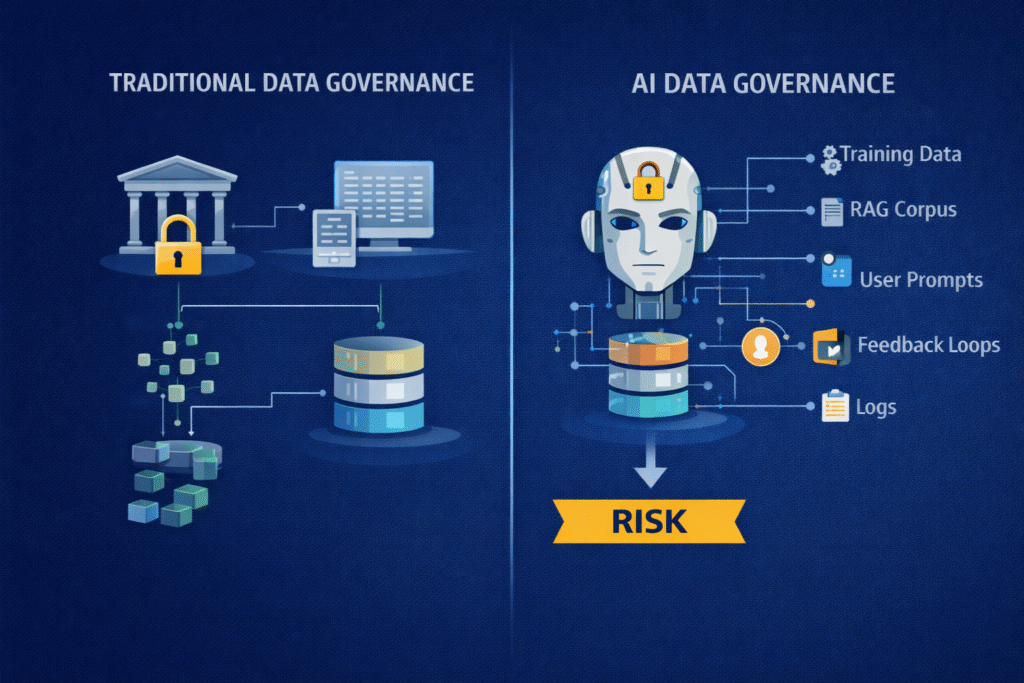
Data governance in the AI context is not traditional data governance
Traditional enterprise data governance was designed for reporting systems, databases, and transactional integrity. AI changes the problem space.
AI data governance must account for:
Training data that permanently shapes model behaviour
Fine-tuning data that introduces subtle biases
Retrieval-augmented generation (RAG) corpora that dynamically influence outputs
User prompts that may contain sensitive or regulated information
Feedback loops that continuously modify system behaviour
Logs and telemetry that themselves become sensitive datasets
This makes AI data governance continuous, dynamic, and risk-bearing, not static or purely administrative.
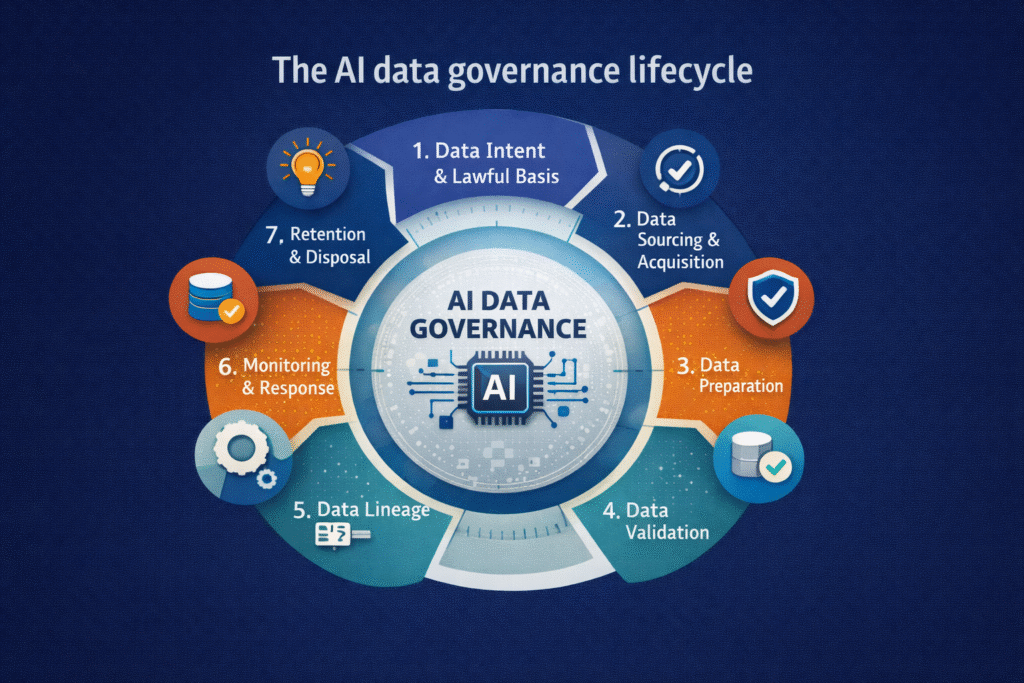
The AI data governance lifecycle
A practical way to understand AI data governance is as a lifecycle that runs inside the AI system lifecycle.
Data intent and lawful basis
Governance begins by defining why data is being used. This includes purpose limitation, lawful basis, sensitivity classification, and constraints on reuse. Without this clarity, AI systems drift into unintended and often non-compliant use.
Data sourcing and acquisition
Where data comes from matters. Provenance, licensing, consent, and supply-chain risk must be assessed before data ever reaches a model. This is especially critical for foundation models and third-party datasets.
Data preparation and conditioning
Cleaning, labelling, transformation, anonymisation, and synthetic data generation are governance activities, not just technical steps. Decisions made here directly affect bias, privacy risk, and downstream explainability.
Data validation and quality assurance
AI requires explicit checks for representativeness, completeness, drift baselines, and fitness for purpose. Poor data quality is one of the most common causes of unreliable AI behaviour.
Data lineage and traceability
Trustworthy AI requires the ability to answer basic questions:
Where did this data come from?
How was it transformed?
Which models use it?
Which outputs were influenced by it?
Lineage and metadata are essential for audits, incident response, and regulatory accountability.
Data use in training, retrieval, and inference
Governance must enforce access control, secure pipelines, and separation of duties across training, RAG, and inference. This is where Zero Trust principles become critical for AI systems.
Monitoring, drift, and incident response
Data does not remain static. Drift, poisoning, misuse, and feedback effects must be continuously monitored, with clear escalation paths when risk thresholds are crossed.
Retention, deletion, and decommissioning
Data governance does not end when data is deleted. AI systems can retain learned behaviours. Governance must address retraining, model retirement, and long-term liability.
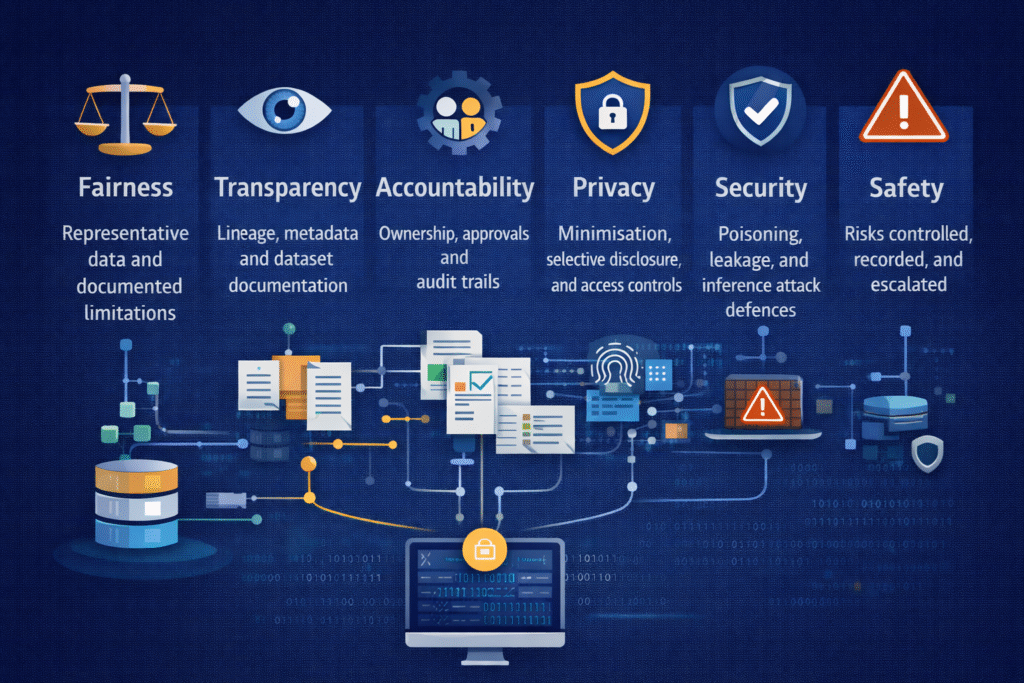
How data governance enables trustworthy and responsible AI
Strong AI data governance directly supports the core pillars of trustworthy AI:
Fairness By ensuring representative, well-understood datasets and documented limitations.
Transparency Through lineage, metadata, and clear documentation of data sources and transformations.
Accountability By assigning ownership, approval gates, and audit trails across the data lifecycle.
Privacy Via minimisation, anonymisation, selective disclosure, and controlled access.
Safety and security By reducing exposure to poisoning, leakage, inference attacks, and misuse.
Responsible AI is not an abstract ethical aspiration. It is the outcome of disciplined governance applied to data before, during, and after AI system deployment.
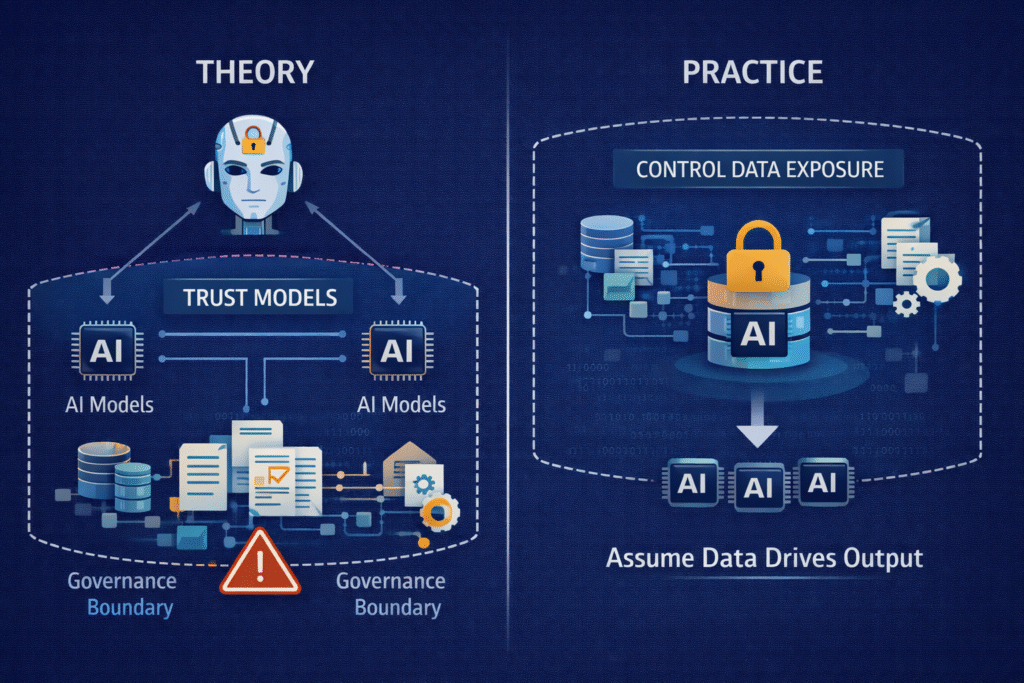
From theory to practice: controlling data, not just models
One of the most important shifts organisations must make is moving from model-centric governance to data-centric governance.
In practice, this means:
Treating sensitive data as selectively disclosed, not broadly shared
Designing AI systems to operate on the minimum data required
Embedding governance controls directly into data pipelines
Assuming that any data exposed to an AI system may influence outputs
This approach aligns with emerging industry thinking that controlling data exposure is often more effective than trying to constrain models after the fact.
Why this matters now
Regulators, customers, and boards are converging on a simple expectation: If an organisation cannot explain, control, and justify how its AI uses data, it cannot credibly claim to operate trustworthy or responsible AI.
Frameworks such as the NIST AI Risk Management Framework and the EU AI Act reinforce this direction, but the underlying reality is more fundamental.
AI does not create trust. Data governance does.
Final thought
Organisations looking to build trustworthy and responsible AI should stop asking only:
“Is our model safe and explainable?”
And start asking:
“Is our data governed well enough to deserve trust at scale?”
Because in AI, governance does not start with algorithms. It starts with data.