

In discussions about trustworthy and responsible AI, data governance is now widely recognised as foundational. Yet many organisations still struggle with a practical question:
How do we actually control data exposure inside AI systems without breaking usability, productivity, or workflows?
For internal corporate AI use cases such as training, retrieval-augmented generation, analytics, and AI agents, traditional controls are proving insufficient. Perimeter security, application-level permissions, and even model-centric safeguards all fail at the same point. Once data is accessed, it is effectively exposed.
A more effective approach is emerging. One that brings Zero Trust principles directly to the data layer itself.
The limits of traditional data protection for AI
Most enterprise data protection strategies assume one of two models.
First, perimeter trust.
If a user or system is inside the network or application boundary, data is assumed to be safe.
Second, application trust.
Access control is enforced by the application, database, or AI
service consuming the data.
Both models break down in AI environments.
AI systems:
- Aggregate data from multiple sources
- Repurpose data beyond its original context
- Retain statistical representations of sensitive information
- Operate across tools, models, and agents
- Expose data indirectly through outputs, logs, and inference behaviour
Once data enters an AI pipeline, traditional access control loses precision. Entire documents are shared when only a few fields are required. Sensitive data is copied into prompts, embeddings, or logs. Controls are applied too late, too broadly, or not at all.
This is a data governance failure, not a model failure.
A data-centric shift: protecting the datum, not the document

A more resilient approach is context-preserving selective encryption.
Instead of encrypting whole files or databases, this approach allows encryption down to a single datum. A field, value, paragraph, or attribute can be protected while the rest of the document remains intact and readable.
The defining characteristics matter.
- Selective encryption at field level
Only sensitive elements are encrypted. Non-sensitive context remains visible. - Context preserved
The document remains usable in its native application such as Word, PDF, spreadsheets, or internal systems. Workflows are not broken. - Cryptographic enforcement
Access is enforced by cryptography rather than application logic or implicit trust.
This represents a fundamental shift. The protection travels with the data wherever it goes.
Attribute-based access control enforced cryptographically
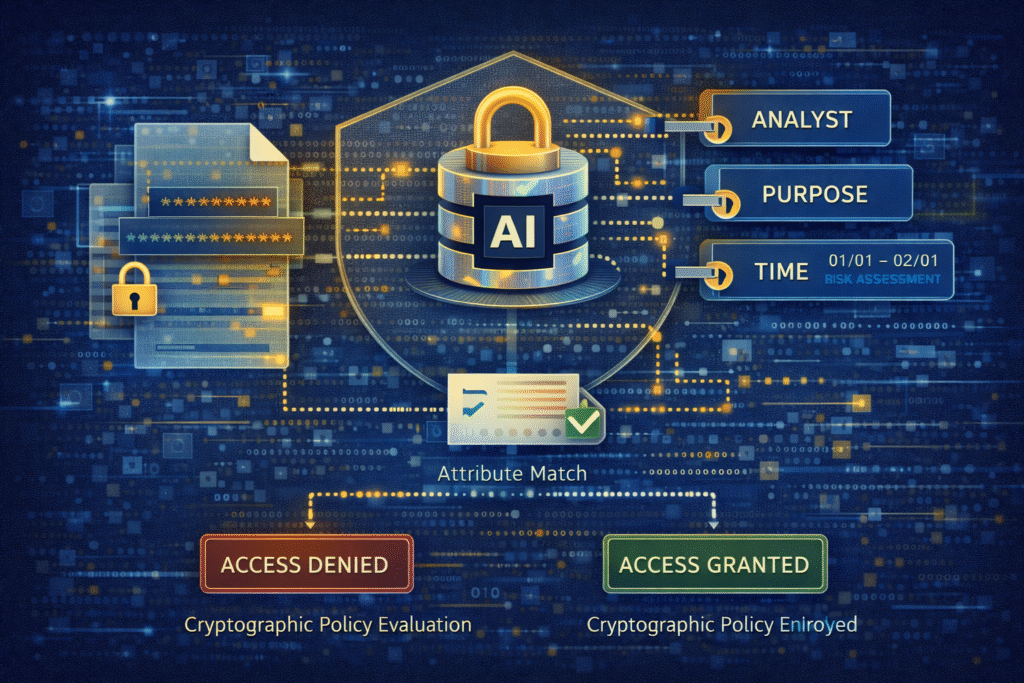
Selective encryption becomes far more powerful when combined with cryptographic Attribute-Based Access Control (ABAC).
In this model:
- Access decisions are based on attributes such as role, clearance, jurisdiction, purpose, time, or project
- Policies are enforced cryptographically, not just administratively
- Decryption occurs only when attributes and policy conditions are satisfied
This matters enormously for AI.
AI systems, agents, and users no longer receive all-or-nothing access. They receive only the data they are explicitly authorised to see, even when working on the same document or dataset.
This aligns directly with:
- Least-privilege principles
- Purpose limitation under GDPR
- Internal data segregation requirements
- AI risk containment strategies
Full auditability: governance you can evidence

Trustworthy AI requires more than prevention. It requires accountability.
A strong data-layer approach includes complete and immutable audit trails that capture:
- Who accessed which data
- When access occurred
- Under which attributes and policies
- For what declared purpose
This transforms data governance from policy statements into evidence-backed control.
For AI governance, this is invaluable:
- Incident investigations become tractable
- Regulatory questions can be answered precisely
- Internal misuse can be detected and addressed
- AI system behaviour can be contextualised and explained
Governance becomes auditable by design.
Zero Trust applied where it matters most

Zero Trust is often discussed in terms of networks, identities, or endpoints. But AI exposes the limitation of that thinking.
AI does not respect perimeters.
It consumes data wherever it is allowed to flow.
By applying Zero Trust directly to the data layer, organisations:
- Remove implicit trust in applications and systems
- Reduce blast radius when AI systems misbehave
- Prevent over-exposure of sensitive information
- Maintain usability without sacrificing control
This is Zero Trust in its most literal form:
never trust access to data unless cryptographically proven and policy-justified.
Why this matters for internal corporate AI
Internal AI use cases are often assumed to be lower risk. In reality, they frequently involve the most sensitive data an organisation holds. This includes:
- Personal data
- Commercially sensitive information
- Intellectual property
- Strategic plans
- Regulatory material
Selective encryption combined with cryptographic ABAC allows organisations to:
- Use internal data for AI safely
- Enable RAG and analytics without wholesale exposure
- Support AI agents without granting excessive access
- Preserve privacy while maintaining productivity
It is one of the strongest privacy-preserving patterns currently available for enterprise AI.
From principles to practice
Responsible and trustworthy AI is often discussed in abstract terms. Trust, however, is not created by intent. It is created by design choices.
Moving from model-centric controls to data-centric, cryptographically enforced governance is one of the most important steps organisations can take today.
Because in AI, the most reliable way to control outcomes remains simple.
Control the data.
Final thought
If data governance is the foundation of trustworthy AI, then it follows that Zero Trust must ultimately live at the data layer.
Not at the perimeter.
Not only in applications.
But inside the data itself.
That is where AI risk is truly managed.