
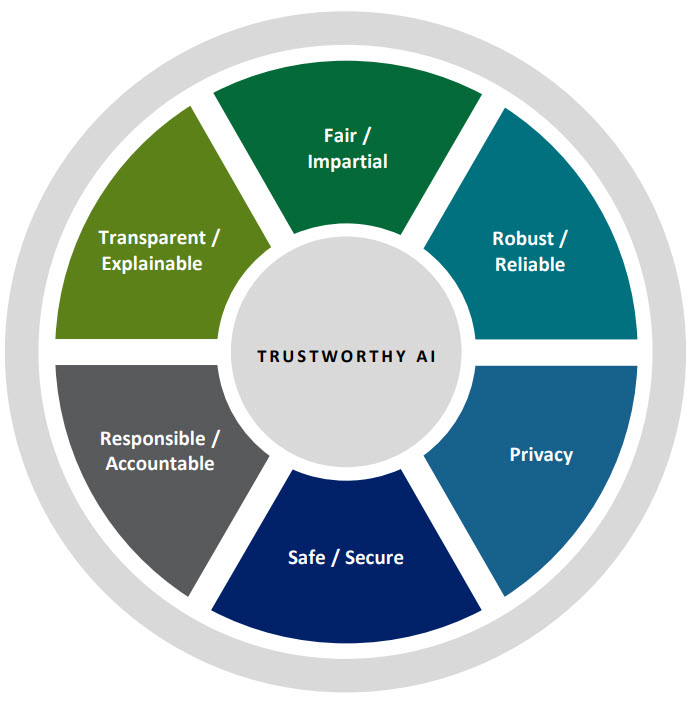
As organisations race to adopt generative AI, agents, and data-driven automation, conversations about trustworthy and responsible AI often focus on ethics statements, model transparency, or regulatory compliance.
These are important. But they are not where trust begins.
Trustworthy AI begins with data governance.
Before models are trained, before prompts are written, and before outputs are evaluated, AI systems inherit their behaviour, risks, and limitations from the data they consume. If data is poorly governed, no amount of downstream controls can fully restore trust.
Why data governance is the foundation of AI trust
AI systems do not reason in the human sense. They learn statistical patterns from data and apply those patterns at scale. This means that data choices are governance choices.
Every decision about:
- what data is collected,
- where it comes from,
- how it is processed,
- who can access it,
- how long it is retained, and
- how it is reused
directly shapes whether an AI system is lawful, safe, fair, secure, and accountable.
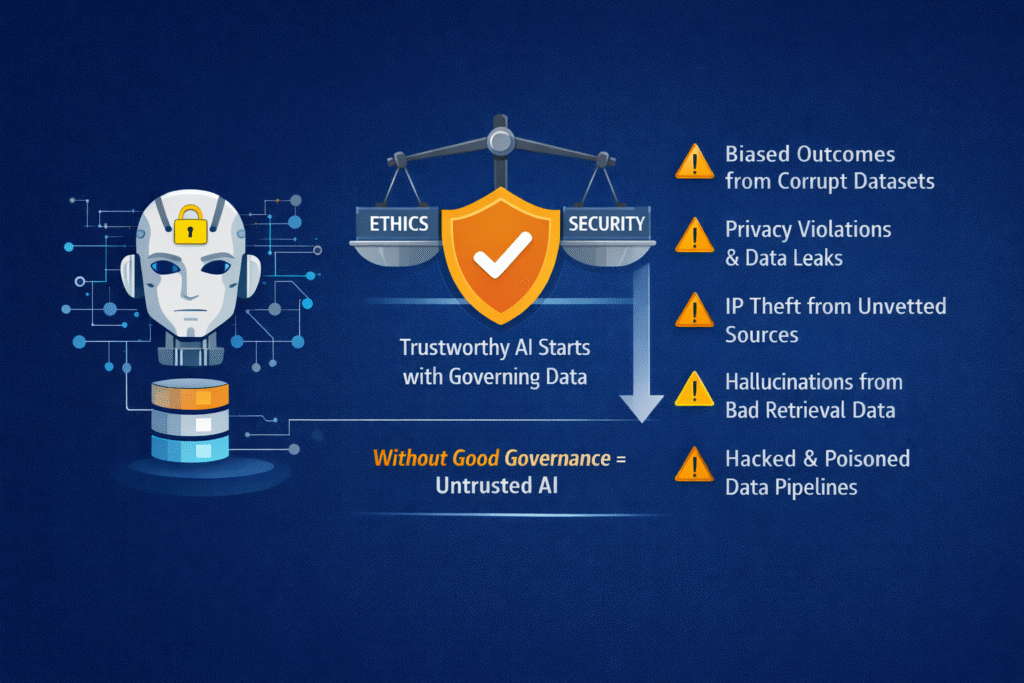
In practice, most AI failures attributed to “model risk” are actually data governance failures:
- Biased outcomes rooted in unrepresentative datasets
- Privacy violations caused by uncontrolled training data
- Intellectual property exposure from scraped or licensed-unclear sources
- Hallucinations amplified by poorly governed retrieval data
- Security incidents driven by data leakage or poisoning
Trustworthy AI does not emerge at inference time. It is established much earlier, through disciplined data governance across the AI lifecycle.
Data governance in the AI context is not traditional data governance
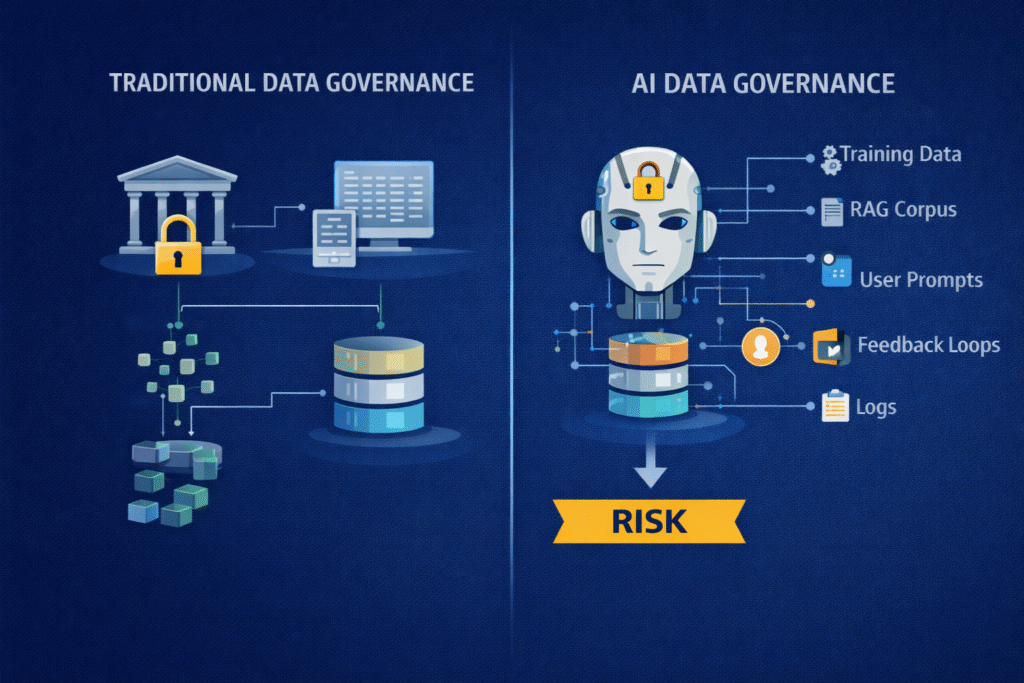
Traditional enterprise data governance was designed for reporting systems, databases, and transactional integrity. AI changes the problem space.
AI data governance must account for:
- Training data that permanently shapes model behaviour
- Fine-tuning data that introduces subtle biases
- Retrieval-augmented generation (RAG) corpora that dynamically influence outputs
- User prompts that may contain sensitive or regulated information
- Feedback loops that continuously modify system behaviour
- Logs and telemetry that themselves become sensitive datasets
This makes AI data governance continuous, dynamic, and risk-bearing, not static or purely administrative.
The AI data governance lifecycle
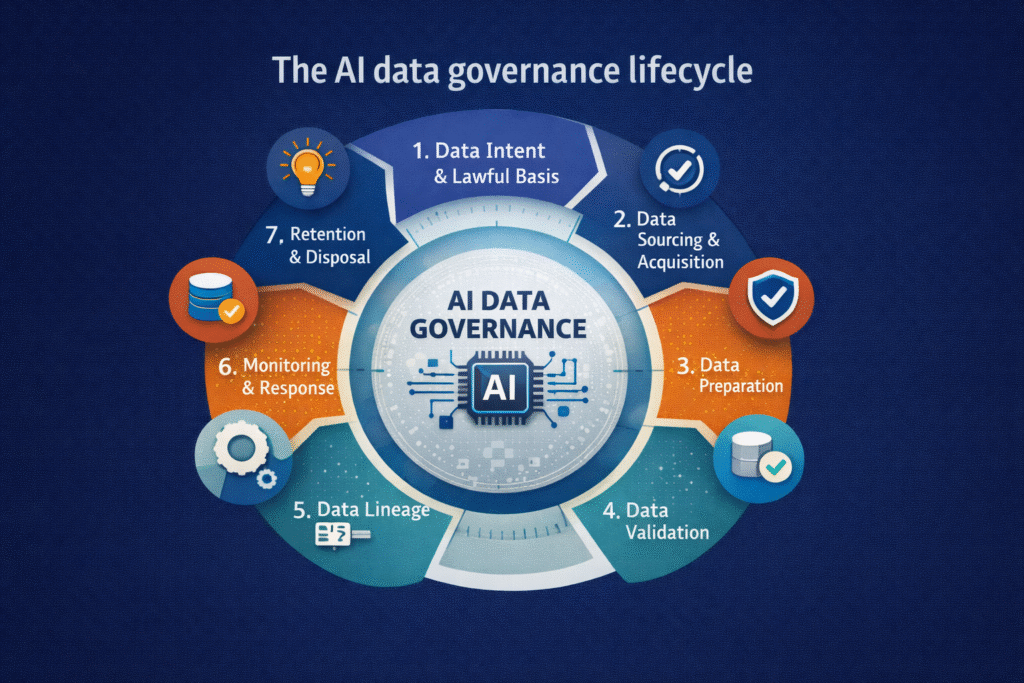
A practical way to understand AI data governance is as a lifecycle that runs inside the AI system lifecycle.
- Data intent and lawful basis
Governance begins by defining why data is being used. This includes purpose limitation, lawful basis, sensitivity classification, and constraints on reuse. Without this clarity, AI systems drift into unintended and often non-compliant use.
- Data sourcing and acquisition
Where data comes from matters. Provenance, licensing, consent, and supply-chain risk must be assessed before data ever reaches a model. This is especially critical for foundation models and third-party datasets.
- Data preparation and conditioning
Cleaning, labelling, transformation, anonymisation, and synthetic data generation are governance activities, not just technical steps. Decisions made here directly affect bias, privacy risk, and downstream explainability.
- Data validation and quality assurance
AI requires explicit checks for representativeness, completeness, drift baselines, and fitness for purpose. Poor data quality is one of the most common causes of unreliable AI behaviour.
- Data lineage and traceability
Trustworthy AI requires the ability to answer basic questions:
- Where did this data come from?
- How was it transformed?
- Which models use it?
- Which outputs were influenced by it?
Lineage and metadata are essential for audits, incident response, and regulatory accountability.
- Data use in training, retrieval, and inference
Governance must enforce access control, secure pipelines, and separation of duties across training, RAG, and inference. This is where Zero Trust principles become critical for AI systems.
- Monitoring, drift, and incident response
Data does not remain static. Drift, poisoning, misuse, and feedback effects must be continuously monitored, with clear escalation paths when risk thresholds are crossed.
- Retention, deletion, and decommissioning
Data governance does not end when data is deleted. AI systems can retain learned behaviours. Governance must address retraining, model retirement, and long-term liability.
How data governance enables trustworthy and responsible AI
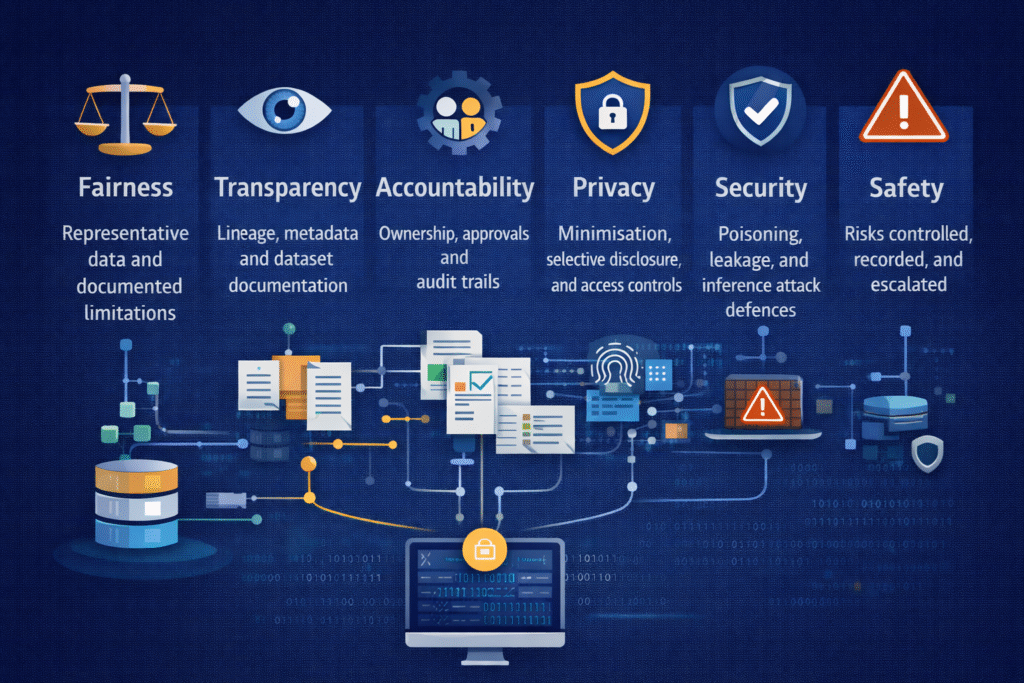
Strong AI data governance directly supports the core pillars of trustworthy AI:
- Fairness
By ensuring representative, well-understood datasets and documented limitations. - Transparency
Through lineage, metadata, and clear documentation of data sources and transformations. - Accountability
By assigning ownership, approval gates, and audit trails across the data lifecycle. - Privacy
Via minimisation, anonymisation, selective disclosure, and controlled access. - Safety and security
By reducing exposure to poisoning, leakage, inference attacks, and misuse.
Responsible AI is not an abstract ethical aspiration. It is the outcome of disciplined governance applied to data before, during, and after AI system deployment.
From theory to practice: controlling data, not just models
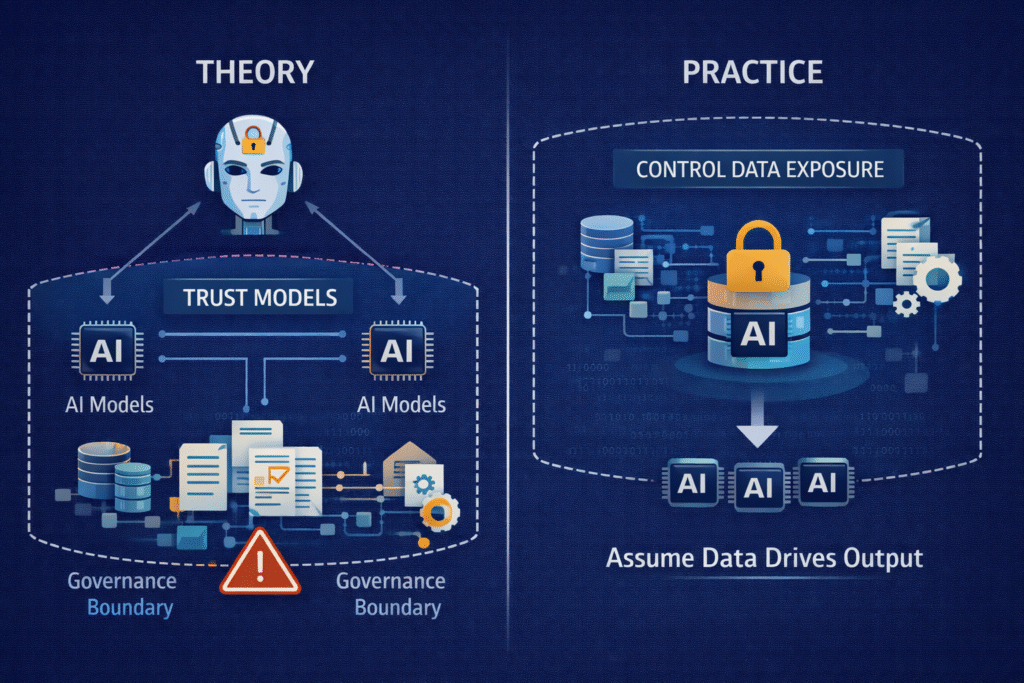
One of the most important shifts organisations must make is moving from model-centric governance to data-centric governance.
In practice, this means:
- Treating sensitive data as selectively disclosed, not broadly shared
- Designing AI systems to operate on the minimum data required
- Embedding governance controls directly into data pipelines
- Assuming that any data exposed to an AI system may influence outputs
This approach aligns with emerging industry thinking that controlling data exposure is often more effective than trying to constrain models after the fact.
Why this matters now
Regulators, customers, and boards are converging on a simple expectation:
If an organisation cannot explain, control, and justify how its AI uses data, it cannot credibly claim to operate trustworthy or responsible AI.
Frameworks such as the NIST AI Risk Management Framework and the EU AI Act reinforce this direction, but the underlying reality is more fundamental.
AI does not create trust. Data governance does.
Final thought
Organisations looking to build trustworthy and responsible AI should stop asking only:
“Is our model safe and explainable?”
And start asking:
“Is our data governed well enough to deserve trust at scale?”
Because in AI, governance does not start with algorithms.
It starts with data.